SQLAlchemy ORM Basics
Last updated on July 27, 2020
Inserting Data #
To create a new record using SQLAlchemy, we follow these steps:
- Create an object.
- Add the object to the session.
- Commit the session.
In SQLAlchemy, we interact with the database using session. Fortunately, we don't need to create session manually, Flask-SQLAlchemy manages that for us. We access the session object as db.session. It is the session object which handles the connection to the database. The session object is also a handler for the transaction. By default, transaction implicitly starts and will remain open until the session is committed or rolled back.
Start the Python shell and create some model objects as follows:
1 2 3 4 5 6 7 8 | (env) overiq@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, Post, Tag, Category
>>>
>>>
>>> c1 = Category(name='Python', slug='python')
>>> c2 = Category(name='Java', slug='java')
>>>
|
Here we have created two Category objects. We can access attributes of an object using the dot(.) operator as follows:
1 2 3 4 5 6 7 | >>>
>>> c1.name, c1.slug
('Python', 'python')
>>>
>>> c2.name, c2.slug
('Java', 'java')
>>>
|
Next, we add the objects to the session.
1 2 3 4 | >>>
>>> db.session.add(c1)
>>> db.session.add(c2)
>>>
|
Adding objects to the session doesn't actually writes them to the database, it only prepares the objects to be saved in the next commit. We can verify this by checking the primary key of the objects.
1 2 3 4 5 6 7 | >>>
>>> print(c1.id)
None
>>>
>>> print(c2.id)
None
>>>
|
The value of id attribute of both the objects is None. That means our objects are not yet saved in the database.
Instead of adding one object to the session at a time, we can use add_all() method. The add_all() method accepts a list of objects to be added to the session.
1 2 3 | >>>
>>> db.session.add_all([c1, c1])
>>>
|
Adding an object to the session multiple times doesn't throw any errors. At any time, you can view the objects in the session using db.session.new.
1 2 3 4 | >>>
>>> db.session.new
IdentitySet([<None:Python>, <None:java>])
>>>
|
Finally, to save the objects to the database call commit() method as follows:
1 2 3 | >>>
>>> db.session.commit()
>>>
|
Accessing the id attribute of the Category object will now return the primary key instead of None.
1 2 3 4 5 6 7 | >>>
>>> print(c1.id)
1
>>>
>>> print(c2.id)
2
>>>
|
At this point, categories table in HeidiSQL should look like this:
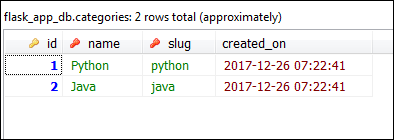
Our newly created categories are not associated with any posts. So c1.posts and c2.posts would return an empty list.
1 2 3 4 5 6 7 | >>>
>>> c1.posts
[]
>>>
>>> c2.posts
[]
>>>
|
Let's create some posts now.
1 2 3 4 5 | >>>
>>> p1 = Post(title='Post 1', slug='post-1', content='Post 1', category=c1)
>>> p2 = Post(title='Post 2', slug='post-2', content='Post 2', category=c1)
>>> p3 = Post(title='Post 3', slug='post-3', content='Post 3', category=c2)
>>>
|
Instead of passing category while creating the Post object, we can also set it as follows:
1 2 3 | >>>
>>> p1.category = c1
>>>
|
Add the objects to the session and commit.
1 2 3 4 | >>>
>>> db.session.add_all([p1, p2, p3])
>>> db.session.commit()
>>>
|
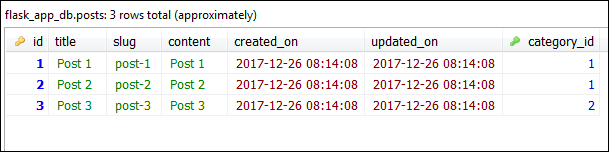
Access the posts attribute of the Category object again, this time you will get a non-empty list like this:
1 2 3 4 5 6 7 | >>>
>>> c1.posts
[<1:Post 1>, <2:Post 2>]
>>>
>>> c2.posts
[<3:Post 3>]
>>>
|
From the other side of the relationship, we can access the Category object to which the post belongs using the category attribute on the Post object.
1 2 3 4 5 6 7 8 9 10 | >>>
>>> p1.category
<1:Python>
>>>
>>> p2.category
<1:Python>
>>>
>>> p3.category
<2:Java>
>>>
|
Remember that, all of this became possible because of the relationship() directive in the Category model. We now have three posts in our database but none of them are associated with any tags.
1 2 3 4 | >>>
>>> p1.tags, p2.tags, p3.tags
([], [], [])
>>>
|
Its time to create some tags. In the shell create Tag objects as follows:
1 2 3 4 5 6 7 8 | >>>
>>> t1 = Tag(name="refactoring", slug="refactoring")
>>> t2 = Tag(name="snippet", slug="snippet")
>>> t3 = Tag(name="analytics", slug="analytics")
>>>
>>> db.session.add_all([t1, t2, t3])
>>> db.session.commit()
>>>
|
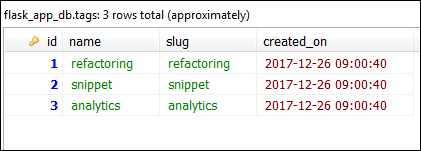
This code creates three tag objects and commits them to the database. Our posts are still not connected to any tags. Here he how we can connect a Post object to a Tag object.
1 2 3 4 5 6 7 8 9 10 | >>>
>>> p1.tags.append(t1)
>>> p1.tags.extend([t2, t3])
>>> p2.tags.append(t2)
>>> p3.tags.append(t3)
>>>
>>> db.session.add_all([p1, p2, p3])
>>>
>>> db.session.commit()
>>>
|
This commit adds the following five records in the post_tags table.
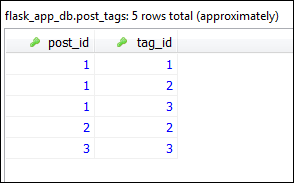
Our posts are now associated with one or more tags:
1 2 3 4 5 6 7 8 9 10 | >>>
>>> p1.tags
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
>>> p2.tags
[<2:snippet>]
>>>
>>> p3.tags
[<3:analytics>]
>>>
|
From the other way around, we can access posts which belongs to a tag as follows:
1 2 3 4 5 6 7 8 9 10 11 | >>>
>>> t1.posts
[<1:Post 1>]
>>>
>>> t2.posts
[<1:Post 1>, <2:Post 2>]
>>>
>>> t3.posts
[<1:Post 1>, <3:Post 3>]
>>>
>>>
|
It is important to note that instead of first committing Tag objects and then associating it with Post objects, we could have done all this at once as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | >>>
>>> t1 = Tag(name="refactoring", slug="refactoring")
>>> t2 = Tag(name="snippet", slug="snippet")
>>> t3 = Tag(name="analytics", slug="analytics")
>>>
>>> p1.tags.append(t1)
>>> p1.tags.extend([t2, t3])
>>> p2.tags.append(t2)
>>> p3.tags.append(t3)
>>>
>>> db.session.add(p1)
>>> db.session.add(p2)
>>> db.session.add(p3)
>>>
>>> db.session.commit()
>>>
|
Notice that in lines 11-13, we are only adding the Post objects to the session. The Tag and Post object are connected via a many-to-many relationship. As a result, adding a Post object to the session implicitly adds its associated Tag objects into the session as well. Even if you still add Tag objects manually to the session, you wouldn't get any error.
Updating Data #
To update an object simply set its attribute to a new value, add the object to the session and commit the changes.
1 2 3 4 5 6 7 8 9 10 11 12 | >>>
>>> p1.content # initial value
'Post 1'
>>>
>>> p1.content = "This is content for post 1" # setting new value
>>> db.session.add(p1)
>>>
>>> db.session.commit()
>>>
>>> p1.content # final value
'This is content for post 1'
>>>
|
Deleting Data #
To delete an object use the delete() method of the session object. It accepts an object and marks it to be deleted in the next commit.
Create a new temporary tag named seo and associate it with the post p1 and p2 as follows:
1 2 3 4 5 6 7 8 9 | >>>
>>> tmp = Tag(name='seo', slug='seo') # creating a temporary Tag object
>>>
>>> p1.tags.append(tmp)
>>> p2.tags.append(tmp)
>>>
>>> db.session.add_all([p1, p2])
>>> db.session.commit()
>>>
|
This commit adds a total of 3 rows. One in the tags table and two in the post_tags table. In the database these three rows look like this:
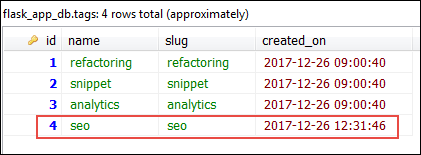
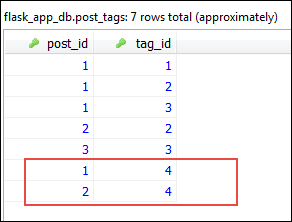
Let's now delete the seo tag:
1 2 3 4 | >>>
>>> db.session.delete(tmp)
>>> db.session.commit()
>>>
|
This commit deletes all the three rows added in the previous step. However, it doesn't delete the post to which the tag was associated.
By default, if you delete an object in the parent table (like categories) then the foreign key of its associated object in the child table (like posts) is set to NULL. The following listing demonstrates this behavior by creating a new category object along with a post object and then deleting that category object:
1 2 3 4 5 6 7 8 9 10 11 | >>>
>>> c4 = Category(name='css', slug='css')
>>> p4 = Post(title='Post 4', slug='post-4', content='Post 4', category=c4)
>>>
>>> db.session.add(c4)
>>>
>>> db.session.new
IdentitySet([<None:css>, <None:Post 4>])
>>>
>>> db.session.commit()
>>>
|
This commit adds two rows. One in the categories table and one in the posts table.
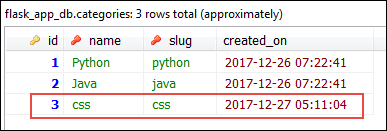
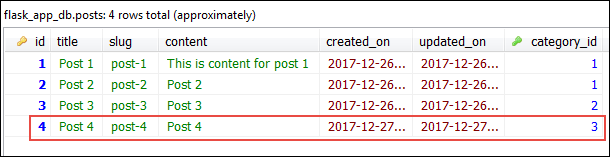
Now let's see what happens when we delete a Category object.
1 2 3 4 | >>>
>>> db.session.delete(c4)
>>> db.session.commit()
>>>
|
This commit deletes the css category from the categories table and sets the foreign key (category_id) of its associated post to NULL.
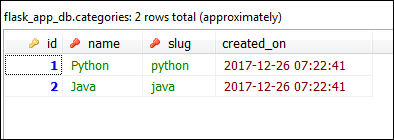
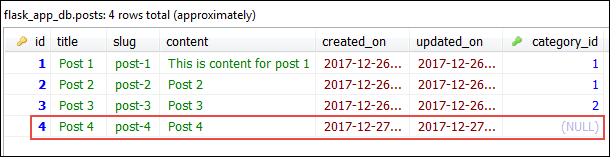
On some occasions, you might want to delete all child records once parent records is deleted. We can achieve that by passing cascade='all,delete-orphan' to the db.relationship() directive. Open main2.py file and modify the db.relationship() directive in the Category model as follows (changes are highlighted):
flask_app/main2.py
1 2 3 4 5 | #...
class Category(db.Model):
#...
posts = db.relationship('Post', backref='category', cascade='all,delete-orphan')
#...
|
From now on, deleting a category will also remove all the posts associated with it. Restart the shell for the changes to take effect, import necessary objects, and create a new category along with a post as follows:
1 2 3 4 5 6 7 8 9 10 | (env) overiq@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db, Post, Tag, Category
>>>
>>> c5 = Category(name='css', slug='css')
>>> p5 = Post(title='Post 5', slug='post-5', content='Post 5', category=c5)
>>>
>>> db.session.add(c5)
>>> db.session.commit()
>>>
|
Here is how the database should look after this commit.
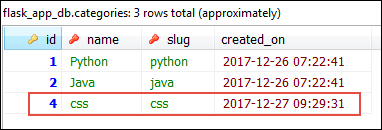
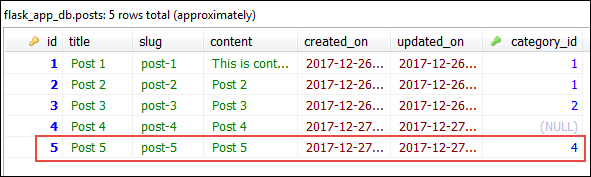
Delete the category now.
1 2 3 4 | >>>
>>> db.session.delete(c5)
>>> db.session.commit()
>>>
|
After this commit database should look like this:
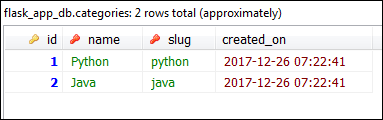
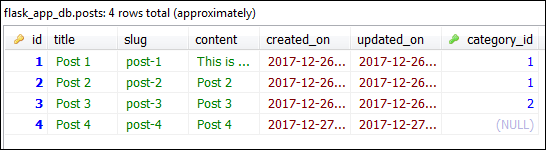
Querying Data #
To query database we use the query() method of the session object. The query() method returns a flask_sqlalchemy.BaseQuery object which is just an extension of the original sqlalchemy.orm.query.Query object. The flask_sqlalchemy.BaseQuery object represents the SELECT statement that will be used to query the database. The following table lists some common methods of flask_sqlalchemy.BaseQuery class.
| Method | Description |
|---|---|
all() |
returns the result of the query (represented by flask_sqlalchemy.BaseQuery) as a list. |
count() |
returns the total number of records in the query. |
first() |
returns the first result of the query or None, if there are no rows in the result. |
first_or_404() |
returns the first result of the query or HTTP 404 Error, if there are no rows in the result. |
get(pk) |
returns an object that matches the given primary key (pk), or None, if no such object is found. |
get_or_404(pk) |
returns an object that matches the given primary key (pk), or HTTP 404 Error, if no such object is found. |
filter(*criterion) |
returns a new flask_sqlalchemy.BaseQuery instance after applying the WHERE clause to the query. |
limit(limit) |
return a new flask_sqlalchemy.BaseQuery instance after applying the LIMIT clause to the query. |
offset(offset) |
return a new flask_sqlalchemy.BaseQuery instance after applying the OFFSET clause to the query. |
order_by(*criterion) |
return a new flask_sqlalchemy.BaseQuery instance after applying ORDER BY clause to the query. |
join() |
return a new flask_sqlalchemy.BaseQuery instance after creating SQL JOIN on the query. |
all() method #
In its simplest form, the query() method can take one or more model class or columns as arguments. The following code returns all the records from the posts table.
1 2 3 4 | >>>
>>> db.session.query(Post).all()
[<1:Post 1>, <2:Post 2>, <3:Post 3>, <4:Post 4>]
>>>
|
Similarly, the following code returns all the records from the categories and tags table.
1 2 3 4 5 6 7 8 | >>>
>>> db.session.query(Category).all()
[<1:Python>, <2:Java>]
>>>
>>>
>>> db.session.query(Tag).all()
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
|
To get the raw SQL used to query the database simply print the flask_sqlalchemy.BaseQuery object as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | >>>
>>> print(db.session.query(Post))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
>>>
>>>
|
In the preceding examples, the data is returned from all columns of the table. We can prevent this by passing the column names explicitly to the query() method as follows:
1 2 3 4 | >>>
>>> db.session.query(Post.id, Post.title).all()
[(1, 'Post 1'), (2, 'Post 2'), (3, 'Post 3'), (4, 'Post 4')]
>>>
|
count() method #
The count() method returns the number of results returned by the query.
1 2 3 4 5 6 7 8 | >>>
>>> db.session.query(Post).count() # get the total number of records in the posts table
4
>>> db.session.query(Category).count() # get the total number of records in the categories table
2
>>> db.session.query(Tag).count() # get the total number of records in the tags table
3
>>>
|
first() method #
The first() method returns only the first result of the query or None if the query returns zero results.
1 2 3 4 5 6 7 8 9 10 | >>>
>>> db.session.query(Post).first()
<1:Post 1>
>>>
>>> db.session.query(Category).first()
<1:Python>
>>>
>>> db.session.query(Tag).first()
<1:refactoring>
>>>
|
get() method #
The get() method returns the instance which matches the primary key passed to it or None if no such object found.
1 2 3 4 5 6 7 8 9 10 | >>>
>>> db.session.query(Post).get(2)
<2:Post 2>
>>>
>>> db.session.query(Category).get(1)
<1:Python>
>>>
>>> print(db.session.query(Category).get(10)) # no result found for primary key 10
None
>>>
|
get_or_404() method #
Same as get() method but instead of returning None when no object found, it returns HTTP 404 Error.
1 2 3 4 5 6 7 8 9 10 11 12 | >>>
>>> db.session.query(Post).get_or_404(1)
<1:Post 1>
>>>
>>>
>>> db.session.query(Post).get_or_404(100)
Traceback (most recent call last):
...
werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on
the server. If you entered the URL manually please check your spelling and try
again.
>>>
|
filter() method #
The filter() method allows us to filter our result by adding WHERE clause to the query. At the minimum, it accepts a column, an operator and a value. Here is an example:
1 2 3 4 | >>>
>>> db.session.query(Post).filter(Post.title == 'Post 1').all()
[<1:Post 1>]
>>>
|
This query returns all the posts where title is "Post 1". The SQL equivalent of the query is:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | >>>
>>> print(db.session.query(Post).filter(Post.title == 'Post 1'))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.title = % (title_1) s
>>>
>>>
|
The string % (title_1) s in the WHERE clause is a placeholder and will be replaced by the actual value when the query is executed.
We can pass multiple filters to the filter() method and they will be joined together using SQL AND operator. For example:
1 2 3 4 5 | >>>
>>> db.session.query(Post).filter(Post.id >= 1, Post.id <= 2).all()
[<1:Post 1>, <2:Post 2>]
>>>
>>>
|
This query returns all the posts whose primary key is greater than or equal to 1 but less than or equal to 2. Its SQL equivalent is:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | >>>
>>> print(db.session.query(Post).filter(Post.id >= 1, Post.id <= 2))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id >= % (id_1) s
AND posts.id <= % (id_2) s
>>>
|
first_or_404() method #
Same as first() method but instead of returning None when the query returns no result, it returns HTTP 404 Error.
1 2 3 4 5 6 7 8 9 10 11 | >>>
>>> db.session.query(Post).filter(Post.id > 1).first_or_404()
<2:Post 2>
>>>
>>> db.session.query(Post).filter(Post.id > 10).first_or_404().all()
Traceback (most recent call last):
...
werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on
the server. If you entered the URL manually please check your spelling and try
again.
>>>
|
limit() method #
The limit() method adds LIMIT clause to the query. It accepts the number of rows you want to return from the query.
1 2 3 4 5 6 7 | >>>
>>> db.session.query(Post).limit(2).all()
[<1:Post 1>, <2:Post 2>]
>>>
>>> db.session.query(Post).filter(Post.id >= 2).limit(1).all()
[<2:Post 2>]
>>>
|
The SQL equivalent of the above queries is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | >>>
>>> print(db.session.query(Post).limit(2))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
LIMIT % (param_1) s
>>>
>>>
>>> print(db.session.query(Post).filter(Post.id >= 2).limit(1))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id >= % (id_1) s
LIMIT % (param_1) s
>>>
>>>
|
offset() method #
The offset() method adds the OFFSET clause to the query. It accepts offset as an argument. It is commonly used with the limit() clause.
1 2 3 4 | >>>
>>> db.session.query(Post).filter(Post.id > 1).limit(3).offset(1).all()
[<3:Post 3>, <4:Post 4>]
>>>
|
The SQL equivalent of the above query is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | >>>
>>> print(db.session.query(Post).filter(Post.id > 1).limit(3).offset(1))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
WHERE
posts.id > % (id_1) s
LIMIT % (param_1) s, % (param_2) s
>>>
|
The strings % (param_1) s and % (param_2) s are placeholders for offset and limit respectively.
order_by() method #
The order_by() method is used to order the result by adding ORDER BY clause to the query. It accepts column names on which the order should be based. By default, it sorts in ascending order.
1 2 3 4 5 6 7 | >>>
>>> db.session.query(Tag).all()
[<1:refactoring>, <2:snippet>, <3:analytics>]
>>>
>>> db.session.query(Tag).order_by(Tag.name).all()
[<3:analytics>, <1:refactoring>, <2:snippet>]
>>>
|
To sort in descending order use db.desc() function as follows:
1 2 3 4 | >>>
>>> db.session.query(Tag).order_by(db.desc(Tag.name)).all()
[<2:snippet>, <1:refactoring>, <3:analytics>]
>>>
|
join() method #
The join() method is used to create SQL JOIN. It accepts table name for which you want to create SQL JOIN.
1 2 3 4 | >>>
>>> db.session.query(Post).join(Category).all()
[<1:Post 1>, <2:Post 2>, <3:Post 3>]
>>>
|
This query is equivalent to the following SQL:
1 2 3 4 5 6 7 8 9 10 11 12 13 | >>>
>>> print(db.session.query(Post).join(Category))
SELECT
posts.id AS posts_id,
posts.title AS posts_title,
posts.slug AS posts_slu g,
posts.content AS posts_content,
posts.created_on AS posts_created_on,
posts.u pdated_on AS posts_updated_on,
posts.category_id AS posts_category_id
FROM
posts
INNER JOIN categories ON categories.id = posts.category_id
|
The join() method is commonly used to get the data from one or more table in a single query. For example:
1 2 3 4 | >>>
>>> db.session.query(Post.title, Category.name).join(Category).all()
[('Post 1', 'Python'), ('Post 2', 'Python'), ('Post 3', 'Java')]
>>>
|
We can create SQL JOIN for more than two table by chaining join() method as follows:
db.session.query(Table1).join(Table2).join(Table3).join(Table4).all()
Let's conclude this lesson by completing our Contact Form.
Recall that, In lesson Form Handling in Flask, we have created a Contact Form to receive feedback from users. As things stand, the contact() view function doesn't save the submitted feedback to the database. It only prints the feedback to the console. To save the feedback to the database, we have to create a new table first. Open main2.py and add the Feedback model just below the Tag model as follows:
flask_app/main2.py
1 2 3 4 5 6 7 8 9 10 11 12 | #...
class Feedback(db.Model):
__tablename__ = 'feedbacks'
id = db.Column(db.Integer(), primary_key=True)
name = db.Column(db.String(1000), nullable=False)
email = db.Column(db.String(100), nullable=False)
message = db.Column(db.Text(), nullable=False)
created_on = db.Column(db.DateTime(), default=datetime.utcnow)
def __repr__(self):
return "<{}:{}>".format(self.id, self.name)
#...
|
Restart the Python shell and invoke create_all() method of the db object to create the feedbacks table.
1 2 3 4 5 6 | (env) overiq@vm:~/flask_app$ python main2.py shell
>>>
>>> from main2 import db
>>>
>>> db.create_all()
>>>
|
Next, modify the contact() view function as follows (changes are highlighted):
flask_app/main2.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #...
@app.route('/contact/', methods=['get', 'post'])
def contact():
form = ContactForm()
if form.validate_on_submit():
name = form.name.data
email = form.email.data
message = form.message.data
print(name)
print(Post)
print(email)
print(message)
# db logic goes here
feedback = Feedback(name=name, email=email, message=message)
db.session.add(feedback)
db.session.commit()
print("\nData received. Now redirecting ...")
flash("Message Received", "success")
return redirect(url_for('contact'))
return render_template('contact.html', form=form)
#...
|
Start the server and visit http://127.0.0.1:5000/contact/, fill the form and submit feedback.
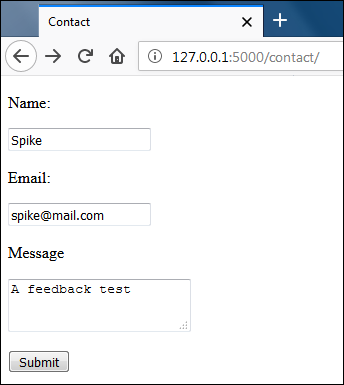
The submitted feedback in HeidiSQL should look like this:

Load Comments