Defining Schema in SQLAlchemy Core
Last updated on July 27, 2020
Creating tables #
Tables in SQLAlchemy are represented as an instance of the Table class. The Table constructor function accepts table name, metadata and one or more columns as arguments. Here is an example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from sqlalchemy import MetaData, Table, String, Column, Text, DateTime, Boolean
from datetime import datetime
metadata = MetaData()
blog = Table('blog', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('published', Boolean(), default=False),
Column('created_on', DateTime(), default=datetime.now)
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
|
Let's step through the code line by line:
- In line 1, we are importing several classes from the
sqlalchemypackage, which we will use to define the table. - In line 2, we are importing
datetimeclass from thedatetimepackage. - In line 4, we are creating a
MetaDataobject. TheMetaDataobject holds all the information about the database and the tables it contains. We useMetaDatainstance to create or drop tables in the database. - In lines 6-14, we are defining the table schema. The columns of a table are created using
Columninstance. TheColumnconstructor function accepts name and type. We can also pass additional arguments to it to define constraints and SQL constructs. The following table lists some commonly used SQL constraints.
| Constraint | Description |
|---|---|
primary_key |
A boolean argument, when set to True, marks the column as the primary of the table. To create a composite primary key, set primary_key to True on each column involved in the key. |
nullable |
A boolean argument when set to False adds NOT NULL constraint while creating a column. Its default value is True. |
default |
It specifies the default value to use in case the value for the column is not specified while inserting a new row. It can take a scalar value or a Python callable. |
onupdate |
It specifies the default value for the column if no value is provided to the column while updating the row. Just like the default keyword argument, it can take a scalar value or a Python callable. |
unique |
A boolean argument if set to True ensures that that values in the column must be unique. |
index |
If set to True creates an indexed column. Its default value is False. |
autoincrement |
It adds the auto increment option to the column. Its default value is auto which means that it will automatically increment primary key every time a new record is added. If you want to auto increment all the columns of involved in the composite primary key, set this argument to True on each of the columns. To disable the auto-increment counter set it to False. |
Column Types #
The type dictates what kind of data a column can take. SQLAlchemy provides an abstraction for a wide range of types. Broadly speaking there are three categories of types.
- Generic Types
- SQL Standard Types
- Vendor Specific Types
Generic Types #
The Generic types refer to the common types which major database backends support. When we use generic types, SQLAlchemy uses the best available type on the database backend while creating tables. For example, in the preceding snippet, we have defined published column as a Boolean. The Boolean is a generic type. If we run the code against PostgreSQL database then SQLAlchemy will use the boolean type provided by PostgreSQL. On the other hand, if we run the code against MySQL, then SQLAlchemy will use SMALLINT type because MySQL doesn't support Boolean type. In the Python code, however, Boolean generic type is represented using bool type (True or False).
The following table lists some generic column types provided by SQLAlchemy and its associated type in Python and SQL.
| SQLAlchemy | Python | SQL |
|---|---|---|
BigInteger |
int |
BIGINT |
Boolean |
bool |
BOOLEAN or SMALLINT |
Date |
datetime.date |
DATE |
DateTime |
datetime.datetime |
DATETIME |
Integer |
int |
INTEGER |
Float |
float |
FLOAT or REAL |
Numeric |
decimal.Decimal |
NUMERIC |
Text |
str |
TEXT |
We can access generic types either from sqlalchemy.types or sqlalchemy package.
SQL Standard Types #
The types defined in this category comes directly from the SQL Standard. Very small number of database backends support these types. Unlike generic types, SQL Standard Types are not guaranteed to work in all database backends.
Just like generic types, you can access these types either from sqlalchemy.types or sqlalchemy package. However, to differentiate them from generic types, names of Standard types are written in all uppercase letters. For example, SQL Standard defines a column of type Array. But currently, only PostgreSQL support this type.
1 2 3 4 5 6 | from sqlalchemy import ARRAY
employee = Table('employees', metadata,
Column('id', Integer(), primary_key=True),
Column('workday', ARRAY(Integer)),
)
|
Vendor Specific Types #
This category defines types that are specific to the database backend. We can access vendor-specific types from sqlalchemy.dialects package. For example, PostgreSQL provides an INET type to store network addresses. To use it we first have to import it from sqlalchemy.dialects package.
1 2 3 4 5 6 | from sqlalchemy.dialects import postgresql
comments = Table('comments', metadata,
Column('id', Integer(), primary_key=True),
Column('ipaddress', postgresql.INET),
)
|
Defining Relationships #
Database tables rarely exist on their own. Most of the time they are connected with one or more tables through various relationships. Primarily, there are three types of relationship that can exist between tables:
- One-to-One relationship
- One-to-Many relationship
- Many-to-Many relationship
Let's see how we can define these relationships in SQLAlchemy.
One-to-Many Relationship #
Two tables are related via a one-to-many relationship if a row in the first table is related to one or more rows in the second table. In the figure below, a one-to-many relationship exists between the users table and the posts table.
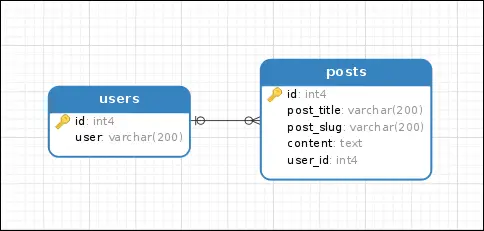
To create a one-to-many relationship pass a ForeignKey object containing the name of the referenced column, to the Column constructor function.
1 2 3 4 5 6 7 8 9 10 11 12 | user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', ForeignKey("users.id")),
)
|
In the above code, we are defining a foreign key on the user_id column of the posts table. It means that the user_id column can only contain values from the id column of the users table.
Instead of passing column name as string we could also pass the Column object directly to the ForeignKey constructor. For example:
1 2 3 4 5 6 7 8 9 10 11 12 | user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey(user.c.id)),
)
|
The user.c.id refers to the id column of the users table. In doing so, remember that the definition of the referenced column (user.c.id) must come before the referencing column (posts.c.user_id).
One-to-One Relationship #
Two tables are related via one-to-one relationship if a row in the first table is related to only one row in the second table. In the figure below, a one-to-one relationship exists between the employees table and the employee_details table. The employees table contains employees records which are public whereas the employee_details contains records which are private.
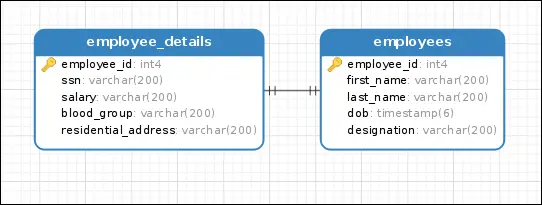
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | employees = Table('employees', metadata,
Column('employee_id', Integer(), primary_key=True),
Column('first_name', String(200), nullable=False),
Column('last_name', String(200), nullable=False),
Column('dob', DateTime(), nullable=False),
Column('designation', String(200), nullable=False),
)
employee_details = Table('employee_details', metadata,
Column('employee_id', ForeignKey('employees.employee_id'), primary_key=True, ),
Column('ssn', String(200), nullable=False),
Column('salary', String(200), nullable=False),
Column('blood_group', String(200), nullable=False),
Column('residential_address', String(200), nullable=False),
)
|
To establish a one-to-one relationship, we define a primary key and foreign key on the same column in the employee_details table.
Many-to-Many Relationship #
Two tables are related via a many-to-many relationship if a row in the first table is related to one or more row in the second table. In addition to that, a row in the second table can be related to one or more table in the first table. To define a many-to-many relationship we use an association table. In the figure below, a many-to-many relationship exists between the posts and the tags table.
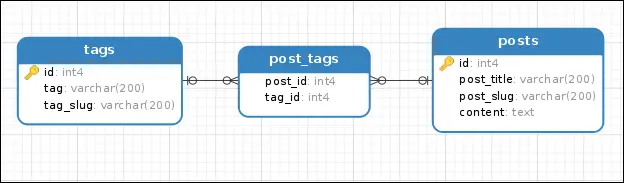
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
)
tags = Table('tags', metadata,
Column('id', Integer(), primary_key=True),
Column('tag', String(200), nullable=False),
Column('tag_slug', String(200), nullable=False),
)
post_tags = Table('post_tags', metadata,
Column('post_id', ForeignKey('posts.id')),
Column('tag_id', ForeignKey('tags.id'))
)
|
You might have noticed that the process of defining the relationship is almost identical to the way we define a relationship in SQL. This is because we using SQLAlchemy Core and the Core lets you do things in the same way as you would do in SQL.
Defining Constraint at the Table level #
In the preceding sections, we have seen how to add constraints and indexes to a column by passing additional arguments to the Column constructor function. It turns out that just as in SQL, we can define constraints and index at the table level. The following table lists some common constraints and the name of the class to create them:
| Constraint/Indexes | Class Name |
|---|---|
| Primary Key Constraint | PrimaryKeyConstraint |
| Foreign Key Constraint | ForeignKeyConstraint |
| Unique Constraint | UniqueConstraint |
| Check Constraint | CheckConstraint |
| Index | Index |
We can access these classes either from sqlalchemy.schema or sqlalchemy package. Here are some examples of how to use them:
Adding Primary Key Constraint using PrimaryKeyConstraint #
1 2 3 4 5 6 | parent = Table('parent', metadata,
Column('acc_no', Integer()),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', name='acc_no_pk')
)
|
Here we are creating a primary key on the acc_no column. This above code is equivalent to the following:
1 2 3 4 5 | parent = Table('parent', metadata,
Column('acc_no', Integer(), primary=True),
Column('acc_type', Integer(), nullable=False),
Column('name', String(16), nullable=False),
)
|
Mainly, the PrimaryKeyConstraint is used to define a composite primary key (a primary key spanning more than one columns). For example:
1 2 3 4 5 6 | parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('acc_no', 'acc_type', name='uniq_1')
)
|
This code is equivalent to the following:
1 2 3 4 5 | parent = Table('parent', metadata,
Column('acc_no', Integer, nullable=False, primary_key=True),
Column('acc_type', Integer, nullable=False, primary_key=True),
Column('name', String(16), nullable=False),
)
|
Creating Foreign Key using ForeignKeyConstraint #
1 2 3 4 5 6 7 8 9 10 11 | parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', Integer, nullable=False),
Column('name', String(40), nullable=False),
ForeignKeyConstraint(['parent_id'],['parent.id'])
)
|
Here we are creating a Foreign Key on the parent_id column which references id column of the parent table. The above code is equivalent to the following:
1 2 3 4 5 6 7 8 9 10 | parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(16), nullable=False)
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('parent_id', ForeignKey('parent.id'), nullable=False),
Column('name', String(40), nullable=False),
)
|
The real utility of ForeignKeyConstraint comes into play when you want to define composite foreign key (a foreign key which consists of more than one columns). For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | parent = Table('parent', metadata,
Column('id', Integer, nullable=False),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
PrimaryKeyConstraint('id', 'ssn', name='uniq_1')
)
child = Table('child', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(40), nullable=False),
Column('parent_id', Integer, nullable=False),
Column('parent_ssn', Integer, nullable=False),
ForeignKeyConstraint(['parent_id','parent_ssn'],['parent.id', 'parent.ssn'])
)
|
Note that passing ForeignKey object to individual columns would not create a composite foreign key, instead, it would create separate foreign keys.
Creating Unique Constraint using UniqueConstraint #
1 2 3 4 5 6 | parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('ssn', name='unique_ssn')
)
|
Here we are defining unique constraint on the ssn column. The optional name keyword argument is used to provide a name to the unique constraint. The above code is equivalent to the following:
1 2 3 4 5 | parent = Table('parent', metadata,
Column('id', Integer, primary_key=True),
Column('ssn', Integer, unique=True, nullable=False),
Column('name', String(16), nullable=False),
)
|
The UniqueConstraint is commonly used to define unique constraint containing multiple columns. For example:
1 2 3 4 5 6 | parent = Table('parent', metadata,
Column('acc_no', Integer, primary_key=True),
Column('acc_type', Integer, nullable=False),
Column('name', String(16), nullable=False),
UniqueConstraint('acc_no', 'acc_type', name='uniq_1')
)
|
Here, I define a unique constraint on acc_no and acc_type, as a result, acc_no and acc_type, when taken together must be unique.
Creating Check Constraint with CheckConstraint #
A CHECK constraint allows us to define a condition that will be evaluated while inserting or updating data. If the condition evaluates to true then the data is saved into the database. Otherwise, an error is raised.
We can add CHECK constraint using the CheckConstraint construct.
1 2 3 4 5 6 | employee = Table('employee', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(100), nullable=False),
Column('salary', Integer(), nullable=False),
CheckConstraint('salary < 100000', name='salary_check')
)
|
Creating indexes using Index #
The index keyword argument which we learned in earlier in this lesson allows us to add index on per column basis. Another way to define index is to use the Index construct. For example:
1 2 3 4 5 6 7 | a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name')
)
|
Here we are creating an index on the first_name column. This code is equivalent to the following:
1 2 3 4 5 6 | a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False, index=True),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
)
|
If your queries involved searching through a particular set of fields then you might get a performance boost by creating a composite index (i.e. an index on multiple columns), which is the primary purpose of Index. Here is an example:
1 2 3 4 5 6 7 | a_table = Table('a_table', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('middle_name', String(100)),
Column('last_name', String(100), nullable=False),
Index('idx_col1', 'first_name', 'last_name')
)
|
Accessing Tables and Columns from MetaData #
Recall that the MetaData object holds all the information about the database and the tables it contains. We can access the table objects, using the following two attributes.
| Attribute | Description |
|---|---|
tables |
returns a dictionary-type object called immutabledict with table name as key and the corresponding Table object as value. |
sorted_tables |
returns a list of Table object sorted in order of foreign key dependency. In other words, the tables which have dependencies is placed first before the actual dependencies. For example, if posts table has a foreign key which refers to the id column of the users table, then the users table is placed first followed by the posts table. |
The following script shows these two attributes in action:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | from sqlalchemy import create_engine, MetaData, Table, Integer, String, Column, Text, DateTime, Boolean, ForeignKey
metadata = MetaData()
user = Table('users', metadata,
Column('id', Integer(), primary_key=True),
Column('user', String(200), nullable=False),
)
posts = Table('posts', metadata,
Column('id', Integer(), primary_key=True),
Column('post_title', String(200), nullable=False),
Column('post_slug', String(200), nullable=False),
Column('content', Text(), nullable=False),
Column('user_id', Integer(), ForeignKey("users.id")),
)
for t in metadata.tables:
print(metadata.tables[t])
print('-------------')
for t in metadata.sorted_tables:
print(t.name) # print table name
|
Expected Output:
1 2 3 4 5 | posts
users
-------------
users
posts
|
Once we have access to the Table instance we can can easily access any relevant detail about the columns as follows:
1 2 3 4 5 6 7 | print(posts.columns) # return a list of columns
print(posts.c) # same as posts.columns
print(posts.foreign_keys) # returns a set containing foreign keys on the table
print(posts.primary_key) # returns the primary key of the table
print(posts.metadata) # get the MetaData object from the table
print(posts.columns.post_title.name) # returns the name of the column
print(posts.columns.post_title.type) # returns the type of the column
|
Expected Output:
1 2 3 4 5 6 7 | ['posts.id', 'posts.post_title', 'posts.post_slug', 'posts.content', 'posts.user_id']
['posts.id', 'posts.post_title', 'posts.post_slug', 'posts.content', 'posts.user_id']
{ForeignKey('users.id')}
PrimaryKeyConstraint(Column('id', Integer(), table=<posts>, primary_key=True, nullable=False))
MetaData(bind=None)
post_title
VARCHAR(200)
|
Creating Tables #
To create the tables stored in the MetaData instance call MetaData.create_all() method with the Engine object.
metadata.create_all(engine)
The create_all() method only creates table if it doesn't already exist in the database. That means you can call create_all() safely multiple times. Note that calling create_all() method after changing the table definition will not alter the table schema. To do that, we can use a database migration tool called Alembic. We will learn more about it in the future lesson.
We can also drop all the tables in the database using MetaData.drop_all() method.
In this tutorial we will be working with the database of an e-commerce application. The database consists of following 4 tables:
customerstable stores all the information about the customer. It consists of following columns:id- primary keyfirst_name- first name of customerlast_name- last name of customerusername- a unique usernameemail- a unique emailaddress- customer addresstown- customer town namecreated_on- date and time of account creationupdated_on- date and time the account was last updated
itemstable stores information about products. It consists of following columns:id- primary keyname- item namecost_price- cost price of itemselling_price- selling price of itemquantity- quantity of item in the stock
ordersstores information about the orders made by the customers. It consists of following columns:id- primary keycustomer_id- foreign key toidcolumn in thecustomerstabledate_placed- date and time the order was placeddate_shipped- date and time the order was shipped
order_linesstores details of items in the each order. It consists of following columns:id- primary keyorder_id- foreign key toidcolumn in theorderstableitem_id- foreign key toidcolumn in theitemstablequantity- quantity of item ordered
The following is an ER diagram of the database.
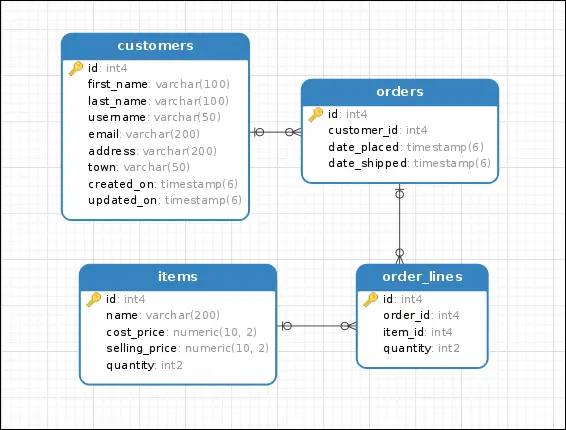
Here is the complete code to create these tables.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | from sqlalchemy import create_engine, MetaData, Table, Integer, String, \
Column, DateTime, ForeignKey, Numeric, CheckConstraint
from datetime import datetime
metadata = MetaData()
engine = create_engine("postgres+psycopg2://postgres:pass@localhost/sqlalchemy_tuts")
customers = Table('customers', metadata,
Column('id', Integer(), primary_key=True),
Column('first_name', String(100), nullable=False),
Column('last_name', String(100), nullable=False),
Column('username', String(50), nullable=False),
Column('email', String(200), nullable=False),
Column('address', String(200), nullable=False),
Column('town', String(50), nullable=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)
items = Table('items', metadata,
Column('id', Integer(), primary_key=True),
Column('name', String(200), nullable=False),
Column('cost_price', Numeric(10, 2), nullable=False),
Column('selling_price', Numeric(10, 2), nullable=False),
Column('quantity', Integer(), nullable=False),
CheckConstraint('quantity > 0', name='quantity_check')
)
orders = Table('orders', metadata,
Column('id', Integer(), primary_key=True),
Column('customer_id', ForeignKey('customers.id')),
Column('date_placed', DateTime(), default=datetime.now),
Column('date_shipped', DateTime())
)
order_lines = Table('order_lines', metadata,
Column('id', Integer(), primary_key=True),
Column('order_id', ForeignKey('orders.id')),
Column('item_id', ForeignKey('items.id')),
Column('quantity', Integer())
)
metadata.create_all(engine)
|
In the next lesson, we will learn how to perform CRUD operations on the database using SQL Expression Language.
Load Comments